Talmud Website is Back in Business

I run a gemara website that periodically goes down. I should have programmed it better, but have all sorts of excuses. (For instance, I’ve looking to port the code from Django to NextJS for a while, and have other tasks I need to handle first.)
The site is mivami, which uses named entity recognition to highlight the Tannaim and Amoraim on any page of gemara and shows a graph of scholastic relationships between them.

What breaks is the daf yomi module. I consult a table coming from Sefaria that spells out the masechet and daf for any day. But they often will change, for instance, the date time format in one column (due to downstram code changes), or the spelling of the masechet. That happened for Bava Kamma, which was spelled something like Baba Kama. Usually I respond by writing an explicit correction in my Python code and redeploying, because I want it up as soon as possible. if maschet == “Hullin”: machechet = “Chullin”
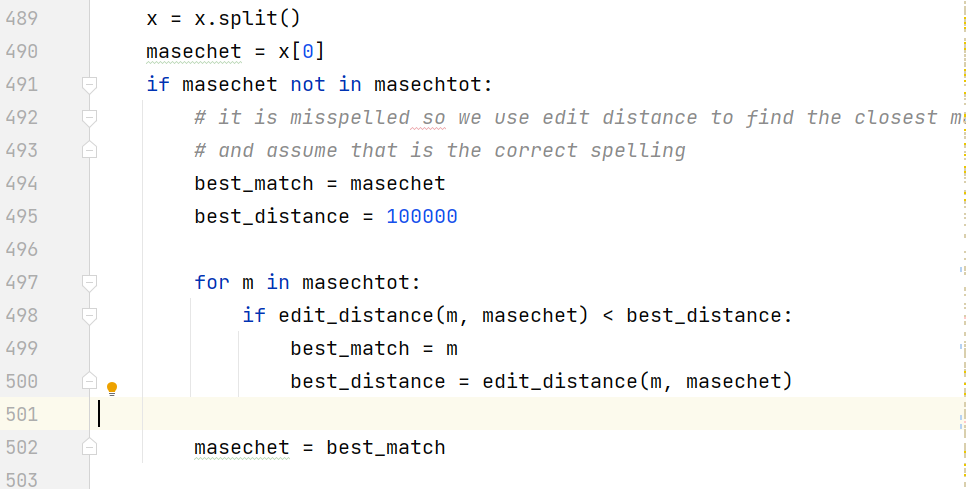
This time, I decided on something more elaborate. I know the “correct” named of all the masechtot as spelled in my database collection. So, I compute the Levenshtein Edit Distance from the masechet spelling given (“Baba Kama”) to each of the candidate maschtot (Bava Kamma, Chullin, Bava Metzia, Horayot, and so on) and choose the closest match. That is called fuzzy string matching. The closest match means the minimum number or “cost” of edit operations of insertion, deletion and substitution. For Hebrew transliteration matching, certain things should not be penalized. So I allow deletion and insertion of vowels or h for free, and substitution of k for c, and so on.
One way of thinking about it is that the masechet listed in the Daf Yomi table has a scribal error, and we are trying to figure out the best original text.
I could have written it myself, but I’ve been playing with Github Copilot which helps you as you type. My usual way of working with it is to write comments with documentation of what I want to guide it in code generation, then supervise the code generation and correct and comment as I see fit. Examples of correction are that it made the matrix via numpy, but I didn’t want that dependency, so I corrected it and commented that I want to use the built-in but slower Python list of list. Some errors I didn’t correct. For instance, it allowed any deletion of h, not only at word-final position, for free.
Here is some of the new code:




and, where I loop to find the best fuzzy match: