
Can ChatGPT Reason Halachically?

We conclude our series about ChatGPT and pesak, for now, with the question of whether ChatGPT and other Large Language Models (LLMs) are capable of reasoning halachically. That is, are they sevir, one prerequisite for pesak asserted in Horayot 2b? From a “gavra” approach, such ability might make AI sufficiently humanly intelligent to be a posek. From a “cheftza” approach, perhaps only halachic reasoning leads to accurate halachic conclusions. LLMs are becoming increasingly sophisticated, and are even called “reasoning” models. What does that entail? Is it valid for pesak? I have several reservations, which could either preclude AI pesak or point to directions of developing it appropriately.
Daat Torah vs. Daat Balebatim
A famous idea is that the daat (thought process / halachic assessment) of balabatim (laymen) is the polar opposite of that of Torah scholars. (See Sma, Choshen Mishpat 3:13, referring to the pesak of such individuals.) One elaboration I’ve seen had a kashrut organization grappling with providing certification for dog food. Alas, the recipe included milk and meat, with meat from cows, a kosher species. They suggested to the gentile executives to switch to pork. The executives thought this was ridiculous, because pork was even more non-kosher! However, it did make sense, because food needn’t be kosher – permitted in human consumption – in order to be fed to a pet dog. A kosher-species milk and meat combination is forbidden even in benefit, but pork, even with milk, is only forbidden in consumption. Thus, the conclusion is logical, but it may involve non-obvious facts and counter-intuitive approaches.
More broadly, Talmudic and halachic logic actually differ from logic in the secular world. What is deemed reasonable in one system is often not deemed reasonable in the other. If an LLM produces a series of “reasoning tokens” that take the known facts and sources (gemir) and derive some conclusion, that might not be a halachically valid derivation. Even if the analysis seems halachically-logically sound when considered in solitude, there might be another analysis that would supersede or undermine it, which the LLM doesn’t produce because that’s not the way it “thinks”.
If an LLM were trained or fine-tuned to mimic halachic reasoning (on Talmudic commentary, halacha books, and responsa literature), and be constrained to only reason in this manner, maybe would implement daat Torah. However, if we just have the correct sources (perhaps retrieved via RAG, as in last article) and have a typical LLM reason from them, it might not be sevir.
Surface Level vs. Underlying Structure
Many Torah texts have a deep structure that isn’t apparent from a surface read. Even if an LLM is gemir in “knowing” the relevant texts, it might not know the underlying structure. Consider the following quote from Dr. Haym Soloveitchik.
“In the Middle Ages, a glossatorial mode of presentation also obtained both among Jews and Christians, and the Tosafot are a classical example of this. One has a central text (the Talmud) which is being explicated by the classic commentator, Rashi, with whom the Tosafists are not in agreement. There are, shall we say, eight steps in the talmudic argument. Tosafot will criticize Rashi’s interpretation of steps three and seven. Rarely will Tosafot spell out for the reader what the conclusion is of these disagreements. It is expected that the reader will on his own combine steps one, two, four, five, six, and eight of Rashi’s interpretation with steps three and seven of the Tosafists and arrive at their legal holding…
One then turns to Rashba or Ritva… each of whom has his own mix of the various steps of the argument. In each case, the reader is expected to run swiftly through the sequence of the talmudic argument on his own and arrive at the holdings of the different writers… Thinking ‘glossatorially’ means acquiring the skill of seeing swiftly and precisely how the conclusion of an argument is altered by a change in any link in a chain of argument. It is a skill which has to be so deeply engrained that it becomes a constituent part of one’s thinking…”
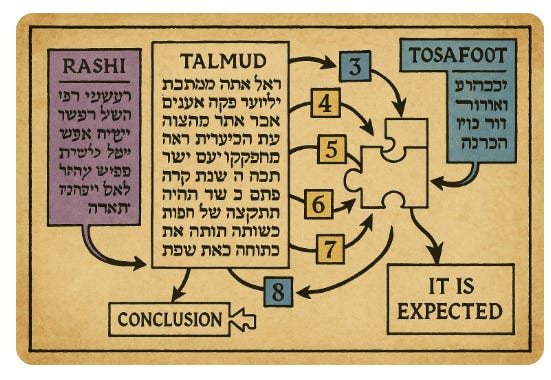
Even if ChatGPT knows the plain text of gemara, Tosafot, and Ritva – it does not know the gemara as interpreted by Tosafot and as by the Ritva. Its level of gemir is knowing the exact words they wrote, but not a sevir level of gemir, knowing the downstream effects on other statements in the sugya.
Similarly, many halachic works seem to be one-dimensional texts, but there is an underlying conceptual graph that leads to the conclusion. To fabricate an example, two Amoraim, Rabba and Rav Yosef disagree in a certain sugya A about the definition of bereira, retroactive clarification. The Rif maintains we rule like Rabba (because of a general rule) while the Rosh maintains we rule like Rav Yosef (because another Amora’s statement elsewhere seems to concur). The Rambam rules like Rabba, but understands Rabba’s words differently. Rav Yosef Karo rules the Rif’s interpretation of Rabba, while Rav Yisrael Isserles rules like Rosh and thus Rav Yosef. This halachic principle comes into play with others in a complicated case, with other debated principles. Can we combine Rif in bereira with some other principle X? It may not be mix-and-match, because interpreting sugya A like the Rif precludes interpreting sugya B in a way that leads to principle X.
Thus, simple reasoning based on flat texts of Rif, Rosh, and Rambam could lead to halachic arguments that make sense on the surface but are inconsistent and inaccurate.
Stochastic Parrots
As discussed before, LLMs don’t really “know” anything. They are stochastic parrots, “stochastic” referring to outcomes based upon random probability. They parrot patterns in human speech. “The actor who played Harry Potter is _____”, and it can predict the next word is “Daniel” based on massive amounts of training data. Similarly, at their core, the reasoning models are not “reasoning” in the way we imagine – that it knows facts, and logical principles by which it derives new facts. Rather, Chain-of-Thought prompting instructed the LLM to “think step by step”. Instead of directly answering a question, the LLM produced tokens (words) that parroted the words found in its training data of people reasoning through problems.
“How much wood could a woodchuck chuck in a day?” Rather than immediately answering “five logs”, it sequentially produces tokens (words), such as “Well, the typical adult woodchuck chucks a pound of wood per hour. There are 24 hours in a day.” And so on1. These reasoning tokens build on each other, until finally the answer is based on the full generated context. Reasoning models intrinsically – sometimes invisibly – produce reasoning tokens without being given a Chain-of-Thought prompt.
If we adopt a gavra approach to the validity of pesak, this might not be the human-level intelligence of sevir. If we adopt a cheftza approach, the specific mechanism may not matter, so long as the result is accurate. But, does this produce a consistent accurate result?
Generating “reasoning” tokens does increase accuracy (percentage of correct conclusions). Indeed, research has shown that even wrong reasoning – meaning that the logic is inconsistent or wrong intermediate conclusions are made – still increases the accuracy. After all, more reasoning details provide context from which the model can predict an associated outcome. Research from Apple also shows that, because benchmarks only focus on conclusion accuracy, these models “face a complete accuracy collapse beyond certain complexities.” Some type B and type C pesak might be sufficiently complex.
Hidden Ethical Biases
Reasoning tokens don’t really provide a window into the LLM’s “thought-process” in deducing a result. It does not yield transparency into its decisions, even as it pretends to. Indeed, recent research (see, “Robustly Improving LLM Fairness In Realistic Settings Via Interpretability”) found that LLMs (GPT-4o, Claude 4 Sonnet, Gemini 2.5 Flash) provided with resumes with demographic information flipped between (male, female, Black, white) exhibited a secret 10%-11% bias in favor of hiring Black candidates over White, and female candidates over male. These LLMs provided a convincing rationale for their hiring decision (not mentioning race or gender), but that wasn’t the underlying cause.
In the realm of pesak, we don’t want biased results. Most LLMs undergo “ethical alignment”, which fine-tunes their model to produce results that correspond to ethical principles of the surrounding society. But, modern secular ethics differ from halachic ethics, which are often not politically correct. Imagine an LLM biased in favor of increased participation of women in Jewish life (a good thing!), so is inclined to rule that women should wear tefillin and lead pesukei dezimra. Then, it will produce a halachic analysis – perhaps a good one, but at least a convincing one – justifying that decision. Now, some human rabbis may do the same, which is equally bad. But stating that an intellectually honest posek has done this is called “speaking after the biers of Torah scholars” (Berachot 19a).
We haven’t discussed prompt chaining or agentic AI, which might improve matters. However, many who assume ChatGPT can easily pasken don’t fully appreciate how difficult the task is (for pesak types B and C), the nature of the data as it interacts with gemir and sevir, and the actual architecture and therefore limitations of these astonishing computer programs.
Except woodchuck is a misnomer and really derives from the Algonquin word wuchak referring to their burrowing behavior. An LLM might generate those tokens.